
Besluitvorming is een vak apart. Verschillende vakgebieden houden zich bezig met besluitvorming en elk vakgebied heeft daarbij zijn eigen benadering. We maken voor deze toekomstverkenning onderscheid tussen drie verschillende benaderingen.
> Cognitieve benadering: Bij deze benadering ligt de focus voornamelijk op de mechanismen van besluitvorming. Een belangrijke vraag binnen deze benadering is op welke wijze oordeelsvorming werkt en op welke wijze mensen keuzes maken.
> Bestuurskundige benadering: Binnen deze benadering wordt besluitvorming voornamelijk gezien als onderdeel van beleidsvorming. Hierbij is er aandacht voor de gehele cyclus van totstandkoming tot implementatie.
> Economische benadering: Bij deze benadering ligt de focus voornamelijk op de strategische keuzes die in het proces gemaakt worden en de belangen die verschillende stakeholders hierin hebben. Binnen deze benadering wordt geprobeerd om besluitvorming te modeleren.
We willen graag geloven dat wij mensen rationele wezens zijn. Dat de keuzes die we maken en de besluiten die we nemen weloverwogen zijn, gebaseerd op kennis en feiten. Maar het besluitvormingsproces is grillig. Beeldvorming en ambities spelen naast feitelijke kennis een belangrijke rol. Deze componenten zijn niet alleen subjectief, maar ook erg veranderlijk. We laten ons continu beïnvloeden door irrationele componenten. Veel besluiten worden dan ook onbewust, bijna automatisch, gemaakt. Denk bijvoorbeeld aan sollicitatiegesprekken. Je weet intuïtief eigenlijk al heel snel of je iemand gaat aannemen of niet (Systeem 1↓Systeem 1 staat voor het snelle, automatische denken. Het gebeurt onbewust en wordt gekoppeld aan instinctieve en emotionele keuzes. Het is intuïtief en kost ons weinig energie. >Hoofdstuk 2.1 ). In de rest van het gesprek ben je voornamelijk bezig met de rechtvaardiging van het gevoel (Systeem 2↓Systeem 2 staat voor het trage, beredeneerde denken. Het is een bewust proces en wordt gekoppeld aan rationele keuzes. Informatie wordt verzameld en afgewogen en de verwerking ervan kost veel energie. >Hoofdstuk 2.1
). Daarbij komt dat de uitleg van onze keuzes achteraf helemaal niet zo goed te herleiden is als we onszelf doen geloven. AI↓De meest dominante associatie met AI is machine learning. Uit onderzoek van de World Intellectual Property Organisation (WIPO) uit 2019 blijkt tevens dat machine learning de meest dominante AI-technologie is die in patentaanvragen is opgenomen. Binnen deze toekomstverkenning richten we ons daarom hoofdzakelijk op machine learning. >Hoofdstuk 1.1 daarentegen, zou keuzes veel meer objectief kunnen maken. Een machine handelt immers rationeel. Maar is dat wel zo? We kijken daarom eerst naar de cognitieve benadering en zetten deze per aspect af tegen de geautomatiseerde besluitvorming van AI.
Het irrationele brein
Een groot deel van ons gedrag en de keuzes die we daarbij maken worden gedreven door instinctieve en emotionele processen in ons brein. Aangezien we evolutionair zijn geprogrammeerd om zoveel mogelijk energie te besparen (en het dus ook logisch is dat we Systeem 1 het meeste werk laten doen) sluipen er wel wat ‘denkfouten’ in onze informatieverwerking. Deze denkfouten worden ook wel cognitive biases genoemd. Zo hebben we sterk de neiging om bewijs te zien dat onze eigen gedachten bevestigt (confirmation bias), hebben we een voorkeur voor mensen die we tot dezelfde groep rekenen als wijzelf (ingroup-outgroupbias) en hebben we de neiging om álle karaktereigenschappen van een persoon of organisatie te waarderen (halo-effect).
Een andere interessante bias is dat we een afkeer hebben van verlies; we reageren sterker op verliezen dan op winsten. Deze bias wordt ondersteund door de prospect theorie van Kahneman uit de jaren ’70. Deze theorie gaat over de wijze waarop mensen besluiten nemen onder risico en met hoge onzekerheid. Mensen blijken inderdaad niet alles keurig op een rijtje te zetten om te bekijken welke optie de hoogste waarde oplevert, maar mensen gaan uit van een referentiepunt; levert dit besluit winst dan wel verlies op. Dat bepaalt of ze risico’s willen nemen of niet. In het geval van winst nemen mensen voorzichtige, risicomijdende besluiten. Wanneer geconfronteerd met verliezen nemen mensen riskantere besluiten. Vaak gaat het om split second decisions en zijn dus meer instinctief dan rationeel.
AI gone wrong
Niet alleen menselijke intelligentie, maar ook AI heeft last van vooroordelen. De output van projecten↓Een algoritme is een wiskundige formule. Het is een eindige reeks instructies die vanuit een gegeven begintoestand naar een vooraf bepaald doel leidt. >Hoofdstuk 1.1 kan namelijk gender en race biases bevatten. De verklaring ervan is simpel. Wanneer de input niet zuiver is, dan is de output dat ook niet.
» Garbage In, Garbage Out. «
Een bekend voorbeeld hiervan is de Twitter chatbot van Microsoft, genaamd Tay. Volgens Microsoft zou de chatbot steeds slimmer worden naarmate je er meer mee zou chatten. Binnen 24 uur na lancering werd Tay echter al offline gehaald, omdat het aan de lopende band racistische uitspraken deed. De chats die mensen met Tay voerden waren niet zo keurig als Microsoft gehoopt had. Nu is dit nog een redelijk naïef voorbeeld. Als je wel eens op social media platforms komt dan had je dit immers kunnen voorspellen. Het wordt echter schrijnender wanneer het aankomt op bijvoorbeeld kredietbeoordelingen, fraudedetectie of sollicitatieprocessen. Zo heeft Amazon in 2014 een AI-applicatie ontwikkeld om sollicitanten te evalueren om zo tot een selectie van de beste kandidaten te komen. Pas een jaar later kwamen ze erachter dat deze seksistisch was. Het probleem was dat het algoritme werd getraind met data van sollicitanten die de afgelopen 10 jaar bij Amazon gesolliciteerd hadden. Aangezien dit in de techbranche voornamelijk mannen zijn, kreeg het algoritme een voorkeur voor mannelijke kandidaten. In 2017 hebben ze de ontwikkeling van de applicatie stopgezet.
Bij dergelijke toepassingen worden vooroordelen – en daarmee digitale discriminatie – juist versterkt. Het probleem is dat data niet divers genoeg is. De vraag daarbij is of er voldoende data beschikbaar is van de meer kwetsbare groepen. Zo worden dialecten door spraakherkenningssoftware nog onvoldoende herkend. Opvallend hierbij is dat ondanks het feit dat we al heel lang weten dat mensen bevooroordeeld zijn, we alsnog historische data gebruiken binnen gevoelige domeinen zoals de rechtspraak. In Amerika is veelvuldig gebruik gemaakt van software om te voorspellen hoe groot de kans is dat een veroordeelde opnieuw de fout in gaat. Uit onderzoek van ProPublica in 2016 blijkt dat deze software bevooroordeeld is in het nadeel van mensen met een donkere huidskleur. Biases van algoritmen worden dus veroorzaakt door biases van mensen.
Uitlegbaarheid
Mensen hebben behoefte aan een uitleg wanneer een bepaald besluit is genomen. Deze behoefte is goed zichtbaar in de zogenaamde ‘loterij paradox’.
Wetenschappers kunnen meedingen naar beurzen door een onderzoeksvoorstel in te dienen. Wanneer je ze vraagt of ze liever willen dat een jury de prijzen uitdeelt, of dat het via loting verloopt, dan blijkt dat ze bijna unaniem aangeven dat ze liever een jury hebben. Via loting ontbreekt namelijk een uitleg. De paradox hierbij is dat ze de beoordeling van de jury ook als ‘loterij’ bestempelen.
Ondanks het feit dat de besluitvorming van mensen dus niet altijd volledig objectief is, wordt deze wel verkozen boven een random proces van loting. Er moet hierbij onderscheid gemaakt worden tussen transparantie, de uitleg en uitlegbaarheid. Transparantie gaat voornamelijk over het proces en de opgestelde criteria vooraf, terwijl de uitleg en uitlegbaarheid over de toelichting op en herleidbaarheid van het besluit achteraf gaan. Bijvoorbeeld bij de jurybeoordeling.
> Transparantie: de beoordeling vindt plaats door middel van een zorgvuldig samengestelde expertjury. Zij scoren eerst individueel alle binnengekomen voorstellen. Op basis van deze scores wordt een top 5 samengesteld, waaruit op basis van een juryoverleg de winnaar wordt gekozen.

> De uitleg: de winnaar van deze aanvraagronde kwam als beste uit het juryoverleg naar voren en scoorde vooral hoog op creativiteit, mate van impact en mogelijkheden voor samenwerking. De jury was met name te spreken over de vernieuwende kijk op het onderzoeksgebied.
> Uitlegbaarheid: verschillende deelnemers blijken zich niet in de uitleg te kunnen vinden. Volgens hen is het winnende voorstel geen vernieuwende kijk op het onderzoeksgebied. In hun ogen is de keuze onvoldoende verdedigbaar en dus niet uitlegbaar.
Uitlegbaarheid is dus erg subjectief en contextafhankelijk, terwijl transparantie en de uitleg veel meer objectief zijn. Daarbij komt dat mensen het prettig vinden om de vinger te kunnen wijzen als ze het ergens niet mee eens zijn. Accountability, oftewel aansprakelijkheid, is dus een belangrijk onderdeel van het besluitvormingsproces. Dus als jij de beurs niet hebt gekregen, dan kun je de schuld altijd bij de jury neerleggen. Het voelt goed om iemand als de schuldige aan te kunnen wijzen. De schuld aan ‘het mechanisme van loting’ geven is wat lastig, aangezien deze geen gezicht heeft. Hetzelfde zie je in de politiek. Het is een soort afstrafmechanisme. Als een politieke partij slecht presteert kun je deze straffen door de volgende keer niet meer op ze te stemmen.
» Besluitvorming is rommelig. «
–– Barbara Vis, UU
Overigens zijn ‘harde feiten’ in dit proces niet altijd doorslaggevend. Uit een artikel uit 2017 van Barbara Vis, hoogleraar Politics & Governance, blijkt dat veel burgers niet alleen slecht, maar vaak ook verkeerd geïnformeerd zijn. Veel mensen schatten bijvoorbeeld het aantal terroristische aanslagen in Europa veel te hoog in. Het grote gevaar hierbij is dat deze mensen hun opvattingen doorgaans niet aanpassen wanneer ze geconfronteerd worden met de daadwerkelijke feiten. Mensen zijn geneigd om informatie te negeren wanneer deze niet overeenkomt met hun eigen opvattingen. Sterker nog, zelfs mensen die wéten dat hun opvattingen feitelijk onjuist zijn, zijn geneigd om bij hun standpunt te blijven wanneer ze vaak genoeg een leugen aangeboden krijgen.
Explainable AI
Besluitvormingsprocessen worden steeds vaker ondersteund door data. Algoritmen maken daarbij steeds vaker zélf de clusters↓Het algoritme gaat dan zelfstandig op zoek naar overeenkomsten in de data en probeert op deze wijze patronen te herkennen. >Hoofdstuk 1.1 , zonder voorgeprogrammeerde labels. Het wordt hierdoor steeds lastiger voor mensen om te achterhalen op basis van welke data de uitkomsten gebaseerd zijn. AI wordt daarom nu nog vaak vergeleken met een black box. Uit onderzoek van de UvA naar geautomatiseerde besluitvorming door AI uit 2018 blijkt dat veel Nederlanders bezorgd zijn dat AI leidt tot manipulatie, risico’s of onaanvaardbare resultaten. Alleen bij meer objectieve besluitvormingsprocessen, zoals de aanvraag van een hypotheek, werden er kansen gezien voor AI. Menselijke controle, menselijke waardigheid, eerlijkheid en nauwkeurigheid worden als belangrijke waarden genoemd bij het nadenken over besluitvorming door AI. Een belangrijke vraag is of het besluitvormingsproces in de toekomst voldoende transparant is en of de uitkomst voldoende uitlegbaar is. Er wordt daarom veel aandacht besteed aan Explainable AI. Cor Veenman, onderzoeker bij TNO, benoemt verschillende aspecten die van belang zijn voor transparantie in het geautomatiseerde besluitvormingsproces:
- Wat zijn de bedrijfsdoelstellingen en waarom?
- Van welke databases wordt gebruik gemaakt en waarom?
- Welke data is gebruikt en waarom?
- Welke modeleringstechnieken zijn gebruikt en waarom?
- Op welke wijze interpreteer je de uitkomsten en waarom?
Er lijkt echter sprake te zijn van een trade off tussen Explainable AI aan de ene kant, waarbij mensen vast willen houden aan de mogelijke verklaringen die het model kan geven, en performance aan de andere kant, waarbij de nauwkeurigheid van nieuwe technieken zoals deep learning↓Deep learning is een machine learning-methode die gebruik maakt van verschillende gelaagde artificial neural networks. >Hoofdstuk 1.1 enorm hoog is, maar het vermogen van verklaarbaarheid deels moet worden opgegeven. Computers leren steeds meer intuïtief. Het is overigens niet zo dat een van de twee het alleenrecht heeft op de toekomst. Het is een ‘knop’ waar designers aan kunnen draaien en waar gebruikers hun wensen in aan kunnen geven.
» Er komt misschien wel een dag dat wij tegen AI zeggen ‘verklaar jezelf’, maar dat de AI zegt ‘you wouldn’t understand it anyway’. «
–– Maarten Stol, BrainCreators
Het is hierbij belangrijk om te bepalen wanneer je welke uitleg geeft en in welke context. Explainability is geen silver bullet, in sommige gevallen kan uitleg juist averechts werken. Een grote uitdaging daarbij is aansprakelijkheid. In theorie kunnen machines misschien wel betere besluiten maken dan mensen, maar het gevoel erbij klopt niet. Je kunt ze namelijk niet tot de verantwoording roepen.
Vertrouwen
Vertrouwen heeft te maken met onzekere situaties en is bij bijna alle interacties tussen twee partijen essentieel. In onzekere situaties blijkt vertrouwen zelfs een significante rol te spelen in het gedrag van mensen. In de basis gaat vertrouwen over het uit handen geven van kwetsbaarheden en het geloof dat de andere partij zich naar verwachting zal gedragen.
Vertrouwen hangt sterk samen met uitlegbaarheid. Je kunt stellen dat hoe meer vertrouwen je ergens in hebt, hoe minder uitleg je nodig hebt. Ik ken bijvoorbeeld niemand die de uitkomsten van zijn rekenmachine controleert. Het is in dat opzicht vergelijkbaar met de auto: ik begrijp niet hoe de motor werkt (en vind het ook niet nodig om te weten), maar ik heb wel een rijbewijs en kan er mee rijden. Ik vertrouw erop dat als een auto op de markt komt, dat deze aan voldoende kwaliteitsnormen en veiligheidstests onderworpen is. Ik heb overigens geen idee aan welke normen en tests, maar ik vertrouw erop dat het goed zit. Veel AI-technologieën staan nog in de kinderschoenen en staan aan het begin van het proces van vertrouwen. Wanneer er richtlijnen zijn opgesteld voor de beheersbaarheid van de technologie en er voldoende tests zijn uitgevoerd zal AI volgens deze zienswijze ook vertrouwd↓Volgens de Gartner Hype Cycle zijn er bij introductie van een nieuwe technologie hoge verwachtingen, tot de eerste failures zich aandienen. Hierna kantelen de verwachtingen en het vertrouwen verdampt. De ontwikkelingen gaan echter door, de marktintroductie wordt doorgezet en de verwachtingen stabiliseren waarna we de technologie accepteren. >Hoofdstuk 1.2 gaan worden. Net als alle andere technologieën die eerder gewantrouwd werden.
Algorithm aversion
Toch lijkt er met AI iets anders aan de hand te zijn. We accepteren al decennialang dat er door de introductie van de auto wereldwijd dagelijks meer dan 3000(!) mensen overlijden in het verkeer. Toch staat de wereld op zijn kop wanneer er als gevolg van een (semi)zelfrijdende auto één persoon overlijdt. In 2018 stopte Uber tests met de zelfrijdende auto’s, nadat er een voetganger was aangereden en overleed in Arizona. Hieruit kun je concluderen dat we strenger zijn voor de technologie dan voor onszelf. Om vertrouwen te hebben in de technologie moeten we kwetsbaarheden uit handen geven aan een ‘onzichtbare entiteit’ die we niet tot de verantwoording kunnen roepen. Ook hier speelt het principe van aansprakelijkheid dus mee. Fouten maken is daarbij menselijk, vinden we zelf. Verschillende citaten en wijsheden ontlenen hieraan hun bestaansrecht.
» Wie niet in staat is een fout te maken, is tot niets in staat. «
–– Abraham Lincoln
Wanneer een algoritme een fout maakt is het echter een ander verhaal. Uit onderzoek van onder andere de University of Penssylvania uit 2014 blijkt dat wanneer mensen een algoritme een kleine en betekenisloze fout zien maken, dat de kans dan groot is dat het vertrouwen volledig verloren gaat. Zelfs wanneer algoritmen aantoonbaar betere besluiten maken, dan nog geven mensen de voorkeur aan hun eigen onderbuikgevoel. Dit wordt door onderzoekers ook wel algorithm aversion genoemd. De onderbouwing van mensen is dat ze meer vertrouwen hebben in het lerend vermogen van mensen, dan in dat van machines. In een experiment werd gevraagd om op basis van toelatingsdata van een MBA-opleidingsprogramma te raden hoe goed studenten het gedaan hadden in het programma. De deelnemers aan het onderzoek werd verteld dat ze een klein geldbedrag konden winnen en dat ze ervoor konden kiezen om zelf een gok te wagen of het over te laten aan een algoritme. Zelfs de deelnemers die gezien hadden dat hun eigen voorspellingen bij eerdere tests slechter waren dan die van het algoritme, maakten alsnog de keuze om zelf de gok te wagen. Alleen wanneer deelnemers de uitkomsten van de voorspelling van het algoritme zelf naar boven of naar beneden konden bijstellen, bleek het vertrouwen omhoog te gaan en verkozen ze het algoritme boven hun eigen voorspelling.
Het lijkt erop dat mensen zich bedreigd voelen door technologie. Uit een onderzoek naar de competitie tussen mensen en robots uit 2019 blijkt dat mensen die verliezen van een algoritme sterk ontmoedigd worden om nog een keer te spelen. In het onderzoek werden deelnemers uitgedaagd om een wedstrijd aan te gaan tegen een algoritme in het tellen van de letter G en in een random reeks letters. Een goed antwoord leverde punten op, terwijl bij een foutief antwoord het scherm 10 seconden bevroren werd. Wanneer ze het algoritme zouden verslaan wonnen ze een geldbedrag. Dit bedrag werd af en toe aangepast om te kijken wat het effect was op de motivatie. Wat bleek, een hoger geldbedrag motiveerde deelnemers niet, het ontmoedigde ze juist. Deelnemers gaven aan zich gestrest te voelen wanneer ze het puntenaantal van het algoritme in hun ooghoek zagen stijgen.
Sympathie
Biases zorgen ervoor dat we eenvoudig beïnvloed worden in het besluitvormingsproces. Zo zijn we eerder bereid om toe te geven aan het verzoek van iemand die we sympathiek vinden. Sympathie, oftewel liking, is een van de zes beïnvloedingsmechanismen die Robert Cialdini beschrijft in zijn boek Influence: The Psychology of Persuasion uit 1984. Overeenkomstig met de ingroup-outgroupbias vinden we voornamelijk mensen sympathiek waar we veel overeenkomsten mee hebben. Denk hierbij aan mensen met een vergelijkbare achtergrond en interesse. Ook aantrekkelijke mensen vinden we sympathieker. We zijn geneigd om aantrekkelijke mensen automatisch allerlei positieve eigenschappen toe te schrijven die ze niet per se bezitten, zoals talent, vriendelijkheid, eerlijkheid en intelligentie. Een typisch geval van het halo-effect.
Vertrouwelijkheid wekt tevens een gevoel van sympathie op. Dit kan ontstaan door herhaaldelijk contact, maar ook door herkenning. We voelen ons bijvoorbeeld meer verbonden met iemand die dezelfde naam heeft als wijzelf. Ook mensen met een fysieke gelijkenis zijn we geneigd om sympathieker te vinden en vertrouwen we sneller.
How do you like me now?
De vraag is of we ons ooit daadwerkelijk kunnen herkennen in machines. De zelfrijdende auto heeft de potentie om het aantal ongelukken op de weg te verlagen. Maar om deze potentie te kunnen benutten moeten mensen wel in willen stappen en de controle uit handen durven geven. Het vertrouwen in de zelfrijdende auto blijft echter nog enorm laag. Uit jaarlijks onderzoek van AAA, een Amerikaanse organisatie die zich inzet voor automobilisten en veiligere wegen en voertuigen, blijkt dat 71% van de Amerikanen in 2019 geen vertrouwen heeft in de zelfrijdende auto. Slechts 19% van de ondervraagden zou hun familie of kinderen met een zelfrijdende auto de weg op sturen.
De vraag is onder welke voorwaarden mensen de technologie gaan omarmen. Frank Verberne, destijds verbonden aan de TU Eindhoven, schreef er in 2015 een proefschrift over: Trusting a virtual driver; similarity as a trust cue. Zijn hypothese is dat het principe van gelijkenis (dat bij mensen sympathie en vertrouwen verhoogt) ook voor technologie zou moeten werken. We geven onze auto’s immers namen en worden boos op een computer als deze niet wil opstarten. Verberne creëerde daarom een digitale avatar met overeenkomstige kenmerken van de proefpersoon en maakte deze op een scherm op het dashboard zichtbaar. Denk bijvoorbeeld aan een vergelijkbaar uiterlijk en een vergelijkbare manier van bewegen en communiceren. Een ‘digitale chauffeur’ blijkt het vertrouwen in de zelfrijdende auto inderdaad te verhogen. Mensen hebben het gevoel dat de auto bestuurd wordt door deze virtuele chauffeur, waarmee we ons vervolgens kunnen vereenzelvigen. Hierbij is de juiste balans echter wel cruciaal; wanneer de avatar teveel op de proefpersoon leek ging het effect verloren.
De vermenselijking van machines is op meerdere fronten zichtbaar. Zo bouwen we robots naar onze gelijkenis, geven we onze virtuele assistenten namen en een menselijke stem en is er zelfs een lag ingebouwd in chatbots. Deze vertraging in de beantwoording van de chatbots moet ervoor zorgen dat de gesprekken natuurlijker aanvoelen. We worden op deze manier wel een beetje voor de gek gehouden, maar waarschijnlijk accepteren we het met liefde. Onze intiemere relatie met technologie vormt een dankbare vorm van inspiratie voor filmmakers. Zo zien we in de film Her uit 2013 hoe de hoofdpersoon verliefd wordt op het besturingssysteem van zijn computer.
De toepasbaarheid van AI in besluitvorming
Besluitvorming is een grillig proces. Zo zijn er verschillende irrationele componenten van invloed op het menselijke besluitvormingsproces. Maar ook algoritmen zijn niet vrij van biases en hebben moeite met uitlegbaarheid. Voordat AI kan worden ingezet voor besluitvorming is het daarom van belang om maatregelen te nemen die de transparantie van het proces en de uitlegbaarheid van de uitkomst waarborgen. Hierbij dient goed nagedacht te worden over de tradeoff tussen performance en explainability.
In de huidige discussies omtrent de toepasbaarheid van AI bij besluitvormingsprocessen wordt er echter onvoldoende onderscheid gemaakt tussen de verschillende typen besluiten en de impact die de besluiten hebben op de betrokkenen. Het maakt nogal een verschil of het gaat om een aanbeveling voor een film, een diagnose op basis van longfoto’s in het ziekenhuis of een advies ten aanzien van een bedrijfsovername. De mate van impact is dus onder andere afhankelijk van de mogelijke risico’s. Naast de cognitieve benadering, moeten we besluitvorming dus ook vanuit de bestuurlijke en economische benadering bekijken.
De impact van besluitvorming
Om te kunnen bepalen wat de toepasbaarheid is van geautomatiseerde besluitvorming, zijn er verschillende factoren die in overweging genomen moeten worden. Deze factoren bepalen de impact van de besluitvorming.
1: Mate van subjectiviteit (hoog/laag): Het is belangrijk om te bepalen in welke mate er overeenstemming is, oftewel consensus, over de juistheid van de uitkomst van het proces. In sommige gevallen is er sprake van een algemeen geldende opvatting en delen de meeste mensen dezelfde mening. In andere gevallen bestaat er geen algemeen geldende opvatting en zijn de opvattingen veel meer subjectief.
2: Mate van onzekerheid (hoog/laag): In het geval van geautomatiseerde besluitvorming is de mate van onzekerheid sterk afhankelijk van de beschikbare data. In sommige gevallen is de data onvolledig en kunnen niet alle aspecten direct afgeleid worden uit de voorhanden zijnde data. De frequentie waarop het besluitvormingsproces zich voordoet heeft hier tevens invloed op. Wanneer de frequentie laag is, is er vaak te weinig data beschikbaar om gegronde uitspraken te kunnen doen. Dit verhoogt de onzekerheid van de output.
3: Mate van risico’s (hoog/laag) Het besluitvormingsproces kan verschillende risico’s met zich meebrengen. Vaak worden risico’s door organisaties uitgedrukt in financiële kosten. Het gaat dan niet zozeer over de kosten van het besluitvormingsproces zelf, maar om de financiële gevolgen van een foutieve beslissing. Daarnaast zijn er ook andere risico’s mogelijk. Denk bijvoorbeeld aan reputatieschade van de organisatie of fysiek letsel van betrokkenen.
To automate or not to automate? That’s the question
De scores op de verschillende factoren bepalen de mate van toepasbaarheid van AI bij besluitvormingsprocessen. Hierdoor ontstaat het volgende assenstelsel, dat we de Automated Decision Making Index (ADMI) genoemd hebben.
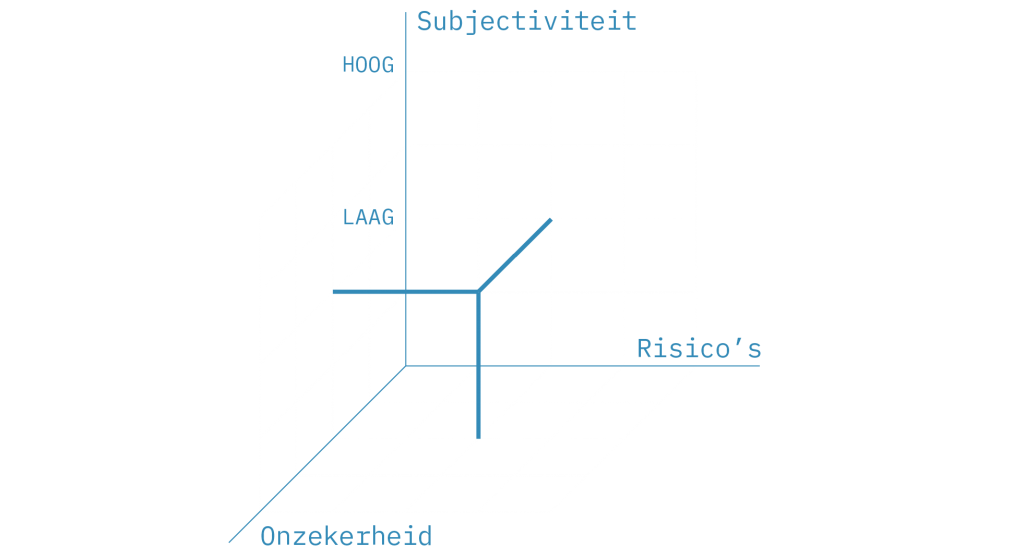
voorbeeld van Subjectiviteit laag/Onzekerheid laag/Risico’s laag
Er zijn op basis van de verschillende factoren acht mogelijke combinaties:
– Subjectiviteit laag / Onzekerheid laag / Risico’s laag
– Subjectiviteit hoog / Onzekerheid laag / Risico’s laag
– Subjectiviteit laag / Onzekerheid hoog / Risico’s laag
– Subjectiviteit laag / Onzekerheid laag / Risico’s hoog
– Subjectiviteit hoog / Onzekerheid hoog / Risico’s laag
– Subjectiviteit hoog / Onzekerheid laag / Risico’s hoog
– Subjectiviteit laag / Onzekerheid hoog / Risico’s hoog
– Subjectiviteit hoog / Onzekerheid hoog / Risico’s hoog
Deze combinaties beschrijven de verschillende typen besluitvorming en bepalen in welke mate AI toepasbaar is bij besluitvormingsprocessen. Er zijn in de basis drie mogelijke opties:
> Automatiseren: AI kan het besluitvormingsproces volledig autonoom doorlopen.
> Ondersteunen: AI kan mensen in het besluitvormingsproces ondersteunen in de vorm van advies.
> Niet automatiseren: AI kan geen rol spelen in het besluitvormingsproces.
Momenteel wordt AI voornamelijk operationeel ingezet. Denk aan slimme AI-toepassingen voor onder andere spoordetectiesystemen en medische diagnoses. Maar ook de aanbevelingen van je streamingsplatform en het automatisch inhalen van je zelfrijdende auto zijn allemaal voorbeelden van operationele taken. Dingen die zich goed lenen voor trial and error, waar veel data is en je gemakkelijk kunt experimenteren. Een voorbeeld is Netflix, waarbij de subjectiviteit van de aanbevelingen wellicht hoog is, maar welke door de lage onzekerheid en risico’s heel goed te automatiseren is. Bij medische diagnoses daarentegen is de subjectiviteit en onzekerheid laag, maar de risico’s dermate hoog dat het waarschijnlijk verstandig is om deze niet volledig te automatiseren, maar door AI te laten ondersteunen.
Bij de zelfrijdende auto wordt vaak het trolley problem aangehaald om te laten zien hoe subjectief de keuzes van de zelfrijdende auto zijn. De vraag is dan wat een auto moet doen wanneer er bijvoorbeeld een groep mensen bij een zebrapad oversteekt en de auto niet meer op tijd kan remmen. Er zijn dan theoretisch gezien twee opties: doorrijden om de inzettende te sparen of uitwijken om de overstekende mensen te sparen. En maakt het dan nog uit wie er oversteken en wie er in de auto zitten? MIT ontwikkelde hiervoor de Moral Machine om te kijken wat je zelf in zo’n situatie zou doen. Toch kun je je afvragen of dit de ontwikkeling van de zelfrijdende auto moet tegenhouden. Hoe vaak komt dit namelijk in de praktijk daadwerkelijk voor? En verhoudt zich dit tot het aantal ongelukken dat er voorkomen kan worden? De computer zal in de basis de juiste keuzes maken, omdat we het er over het algemeen wel over eens zijn wat er goed en fout is in het verkeer. Het is daarom van belang om de verschillende factoren goed te overwegen en tegen elkaar af te zetten. Hierbij dient tevens rekening gehouden te worden met de voordelen die de inzet van AI bij besluitvormingsprocessen kan hebben, zoals het tegengaan van files en het verminderen van het aantal verkeersdoden.
De vraagt blijft momenteel nog of je algoritmen in de toekomst kunt inzetten bij strategische vraagstukken. Denk bijvoorbeeld aan een bedrijfsovername. De uitdaging zit in het feit dat er relatief gezien weinig data beschikbaar is. Er zijn dus veel onzekerheden en de risico’s zijn hoog. Voorlopig zou je dus kunnen concluderen dat het bij strategische vraagstukken waarschijnlijk bij aanbevelingen door AI blijft.